ZFS en détails
Les caractéristiques de ce système de fichiers sont sa très haute capacité de stockage, l’intégration de tous les concepts précédents concernant les systèmes de fichiers et la gestion de volume en un seul produit. Il intègre la structure On-Disk, il est léger et permet facilement la mise en place d’une plate-forme de gestion de stockage.
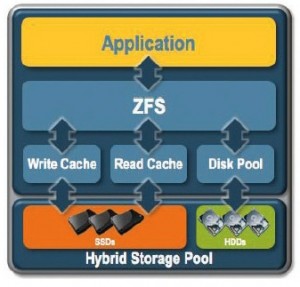 Qu’est-ce que ZFS?
Qu’est-ce que ZFS?
- ZFS est un puissant système de stockage de données qui combine à la fois la gestion des volumes et le système de fichiers
- ZFS est transactionnel Copy-on-Write et toujours consistant. Lorsque des nouvelles données doivent être écrites, ZFS utilisera des nouveaux blocs plutôt que d’écraser les anciens, de manière à conserver les deux. De plus, ZFS travaille de manière transactionnelle, à la manière des DB. Si vous exécutez un benchmark, les opérations vont se retrouver dans un « transaction group » (TXG) et les queries vont être exécutées en mode « burst » à intervalles réguliers (30 secondes).
- ZFS est un système de fichiers 128 bits, sa capacité est de 16 milliards de milliards de fois celle des systèmes de fichiers 64 bits actuels
- ZFS utilise des checksum pour vérifier l’intégrité de ses données
- ZFS adore la RAM et les SSD, et sait comment les utiliser. ZFS utilise la RAM comme cache intelligent (ARC: Adaptive Replacement Cache) et y conserve jusqu’à 4 listes de cache parmi lesquelles: la MRU (Most Recently Used) et la MFU (Most Frequently Used).
La RAM est également utilisée comme espace de « prefetch » et de « Vdev Read-Ahead », ZFS rappatrie vers la RAM les données que vous êtes susceptibles de demander pour pouvoir les fournir plus rapidement.
ZFS se résume en 2 commandes: zpool pour la création des pools et zfs pour la création des datasets
Création d’un pool
Un pool peut être créé très simplement:
zpool create pool_name disk1 disk2 disk3 zpool status
La première commande crée le pool tandis que la deuxième montre que le pool a été créé et monté dans l’arboresence. Un df -h vous montrera que l’espace libre correspond à la somme des capacités des disques (striping).
L’espace de stockage est disponible et utilisable tel quel mais si vous voulez profiter de la technologie de ZFS, il vous faudra créer un dataset.
Création d’un dataset
Un dataset est un conteneur pour lequel certaines propriétés peuvent être configurées. La liste des datasets peut être affichée grâce à la commande zfs list. Leur création est également très simple:
zfs create pool_name/dataset_name
Ce qui a pour effet de créer et de monter automatiquement le dataset comme un subdirectory de la racine zfs, ici pool_name (à ne pas confondre avec la racine du système d’exploitation).
Les zpools et leurs vdevs
Un pool est créé à partir de un ou plusieurs « vdevs » (Virtual Devices), composés eux-mêmes de un ou plusieurs périphériques physiques. Ces vdevs peuvent donc être du type:
- disk: un disque réel. Pour afficher les disques, vous pouvez utiliser la commande BSD suivante:
camcontrol devlist diskinfo -v /dev/ada0
- file: un fichier (/vdevs/vdisk001), idéal pour faire des tests mais non-recommandé pour la production. Ces fichiers doivent faire minimum 128Mo et être pré-alloués grâce à la commande suivante sous BSD:
dd if=/dev/zero of=vdisk001 bs=1024k count=128
- mirror: deux ou plusieurs disques en miroir
- raidz1/2: trois disques ou plus en RAID5/6. Le raidz2 est en fait un raidz1 mais avec une double parité
- spare: un disque « roue de secours »
- log (aka ZIL SLOG): un périphérique dédié au logs (typiquement SSD)
- cache (aka L2ARC): un périphérique dédié au cache de lecture (typiquement SSD)
Ces différents vdevs peuvent être combinés ensemble pour former des raids hybrides, par exemple:
zpool create (-f) mypool mirror disk1 disk2 mirror disk3 disk4
crée un RAID1+0 à partir de 2 vdevs (2 miroirs). L’option -f est nécessaire si le pool a été créé précédemment puis supprimé.
zpool create mypool raidz disk1 disk2 disk3 log ssd1 cache ssd2 spare disk4 disk5
crée un raid hybride composé de 4 vdevs
Scrubs
Un scrub permet de lire l’entièreté des données contenues dans le pool afin de vérifier si celles-ci sont toujours consistantes et de réparer les erreurs si il y en a. La commande zpool scrub doit donc être lancée périodiquement via un cron. Une fréquence d’une fois par semaine pendant les heures creuses est suffisante.
Portabilité
Les pools peuvent être importés et exportés. Cette technique est utilisée lors des reboot: la configuration est exportée lors de l’extinction pour être ensuite importée à l’allumage. De la même manière, les disques peuvent être déplacés dans une autre machine, un simple zpool import permettra de récupérer votre pool grâce aux infos contenues dans les headers des disques.
Maintenance
Vous pouvez aisément remplacer un périphérique défectueux par un disque de remplacement (spare) grâce à la commande:
zpool replace old_dev new_dev
Les périphériques peuvent être mis « offline » (pour pouvoir travailler dessus sans que ZFS ne se mêle de ce que vous faites) ou « online » grâce aux commandes:
zpool online vdev1 zpool offline vdev1
La reconstruction d’un vdev est appelée « resilver ».
Les commandes zpool attach et zpool detach permettent d’ajouter ou de retirer des périphériques à un vdev redondant (mirror).
Augmentation de la capacité d’un pool
Un pool peut être étendu grâce à la commande
zpool add pool_name vdev
Il n’est pas encore possible de diminuer la taille d’un pool (shrink).
Propriétés
Les propriétés peuvent être affichées en exécutant la commande:
zpool get all pool_name
et modifiées avec
zpool set autoreplace=on dataset_name
Parmi les propriétés d’un pool, les plus importantes sont failmode, autoreplace et listsnapshots.
Le failmode décrit la façon dont ZFS va réagir si quelque chose se passe mal: WAIT pour attendre que le problème se répare, CONTINUE pour continuer malgré le problème, PANIC pour stopper le système.
Listsnapshots permet d’afficher ou de masquer les snapshots lors d’un zfs list (désactivé par défaut).
Autoreplace permet de remplacer automatiquement un périphérique défectueux par un spare.
Historique
zpool history dataset_name
permet d’afficher les commandes qui ont été exécutées sur le dataset.
Dimensionnement
ZFS réserve 1/64ème de la capacité des pools pour la sauvegarde de données propre au Copy-on-Write.
Les datasets
Les datasets sont des points de contrôle, ils peuvent être imbriqués et héritent des propriétés de leur parent (appelé « stub »). Pour créer un dataset, rien de plus facile:
zfs create mypool/dataset
Les ZVols
Les ZVols sont des datasets qui représentent un volume (ensemble de blocs) plutôt qu’un système de fichier. Ce volume peut être partitionné, formatté en ext ou autre, et peut être créé en « thin provisioning » (sparse). C’est utilisé dans le cas des iSCSI où l’on peut avoir besoin d’assigner un LUN composé de blocs.
Propriétés
Les propriétés peuvent être affichée avec la commande:
zfs get all pool/dataset
et modifiées avec
zfs set key=value pool/dataset
- Disk space used vs Disk space referenced:
L’espace disque utilisé comptabilise la quantité de données, tandis que l’espace disque référencé comprend les snapshots en plus. - Quota vs Reservation
Le quota est une limite, tandis que la réservation va pré-allouer l’espace mémoire. Vous préfèrerez donc utiliser un quota pour un utilisateur simple et une réservation pour un CEO. - Record size
ZFS utilise des tailles dynamiques pour les blocs, mais la taille maximum est celle spécifiée par le record size. Au-delà, les données seront fractionnées. Ce paramètre ne doit pas être modifié, à moins que vous ne fassiez du fine-tuning pour une base de données (si c’est le cas, vous préfèrerez un record size de 8k). - Mount point
Définit le point de montage - Share NFS
Exporte le dataset pour en faire un NFS - Checksum
Il est déconseillé de le désactiver car il apporte une meilleure sécurité de l’intégrité des données et son impact sur les performances est négligeable. - Compression
Permet de compresser les données - atime
Garde une trace des dates d’accès aux fichiers, autrement dit ça génère des accès disques inutiles. Désactivez cette option avec la commande:zfs set atime=off pool_name
- copies
Détermine le nombre de copies à créer lors de la création de données. Utile lorsqu’on utilise un pool composé d’un seul périphérique, afin d’avoir une copie des fichiers en cas de corruption. - sharesmb
Permet de partager le dataset via samba (CIFS) - ref_quota et ref_reservation
Idem que pour les quotas et les réservations mais sur l’espace référencé cette fois
Les snapshots
Le snapshot crée un instantané de l’état des données au moment où il est déclenché. La restauration des données peut se faire par fichier ou par dataset complet. Le snapshot est identifié par le symbole @. De par la fonctionnalité « Copy-On-Write » de ZFS, les snapshots ne consomment pas d’espace supplémentaire. Pour prendre un snapshot, il suffit d’exécuter:
zfs snapshot pool/dataset@snapshot_name
Si la propriété snapdir est mise à « visible » (au lieu de « hidden »), vous verrez apparaître un directory .zfs contenant les dossiers des snapshots. Ces dossiers peuvent être browsés normalement (en read-only) pour récupérer des données.
# zfs snapshot -r raidpool@`date +%Y%m%d` # zfs rename raidpool@`date +%Y%m%d` raidpool@today # ls /mnt/raidpool today # zfs list -r -t snapshot NAME USED AVAIL REFER MOUNTPOINT raidpool@today 128K - 244K - raidpool/share1@today 244K - 3.26G - # zfs list -t snapshot -o name,creation raidpool NAME CREATION raidpool@today Wed Dec 11 18:00 # zfs destroy raidpool@today # zfs list -H -o name -t snapshot | xargs -n1 zfs destroy
Attention à la dernière commande qui supprimera tous vos snapshots!
Rollback
La fonction rollback permet de restaurer un snapshot de manière irréversible. Les snapshots plus récents seront perdus.
Clones
La fonction clones permet de créer un dataset (read-write) à partir d’un snapshot. Ce clone agit comme un dataset normal, sauf qu’il ne consomme pas d’espace. Ca peut être utile pour tester un environnement contenant d’anciennes données sans perturber les données actuelles.
Un clone peut être promu par la suite pour ne plus dépendre du dataset et avoir son propre espace disque.
Les clones peuvent être répliqués, en les transformant en data stream et en les envoyant vers un pipe:
zfs send pool/dataset@snap1 | ssh root@remote_machine zfs recv pool/dataset_backup
Ici nous avons envoyé le snapshot par ssh sur une autre machine, mais nous aurions très bien pu aussi l’envoyer vers un fichier encrypté.
Partages
ZFS permet de très facilement partager les datasets via NFS, CIFS et iSCSI en modifiant simplement le paramètre correspondant à « on ».
Monitoring I/O
2 façons de mesurer les entrées/sorties:
- au niveau du Virtual File System (VFS) avec fsstat (le plus important)
- au niveau des disques physiques avec iostat
Conclusion
Le système ZFS est d’une simplicité halucinante. Les mécanismes qui se cachent derrière sont le fruit d’une réflexion efficace et vont à coup sûr bouleverser les habitudes des storage admins.
Trackback from your site.